POJ的字母集比较独特,以至于没有一种较流行的西方语言的字母集能包含POJ的字母集,这使得默认的以西方语言为基础的OCR不能对POJ那些带diacritics的字母进行有效识别。因此我们需要定制自己的OCR。Tesseract OCR是HP在1995年以前开发的开源OCR,支持对新的字符集进行训练从而能支持新的语言。Tesseract OCR有一定的局限性,不过POJ的特点不会hit到这些限制。因此有可能用Tesseract OCR来对POJ进行有效识别。
Tesseract OCR的局限:Tesseract can only handle left-to-right languages. While you can get something out with a right-to-left language, the output file will be ordered as if the text were left-to-right. Top-to-bottom languages will currently be hopeless.
Tesseract is unlikely to be able to handle connected scripts like Arabic. It will take some specialized algorithms to handle this case, and right now it doesn't have them.
Tesseract is likely to be so slow with large character set languages (like Chinese) that it is probably not going to be useful. There also still need to be some code changes to accommodate languages with more than 256 characters.
下面是我测试的结果:
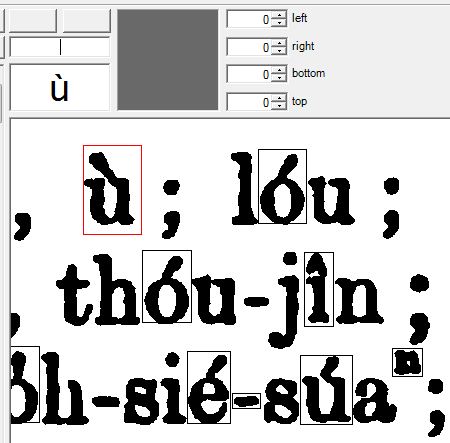
1. 对William正文第2页的POJ字符(主要是带diacritic的)进行训练。


2. 将训练结果与原来Tesseract提供的英语训练结果合并,使得Tesseract可以识别不带diacritic的正常英语字符。
3. 对William正文第3页进行试识别。
4. 识别结果:aCC0l1I1t, siàu-ba̍k. boolc, siàu-phõu. to enter, chiēⁿ-siàu ; léh-
siàu ; kì-siàu. settle, hôiⁿ-siàu; siàu-ba̍k chheng-tshó. owe,
khiàm-siàu. square, ap-siàu . collect, thó-siàu. manage,
hūaⁿ-siàu. make up, su̍g—siàu. on account Q/1 in-ũi. on no
account, būan-būan put-khó; tùan-tùan m̄-hó. cannot a.
fcrr, put·kói; siēⁿ-m̄-phùa; siēⁿ-m̄-tshut. an cwcmmt qf
any event, éh pun·nīng·thiaⁿ; Qiāng-nīni-tàⁿ. 字符 样本数
- 77
; 57
, 34
. 27
h 27
t 24
g 19
i 17
ⁿ 15
à 14
õ 13
a 12
ó 11
á 9
e 9
ē 9
k 9
m 9
ũ 9
â 8
c 8
ô 8
u 8
ú 8
ù 8
é 7
ō 7
s 7
a̍ 6
ê 6
e̍ 5
m̄ 5
o̍ 5
ā 4
ẽ 4
ī 4
o 4
ū 4
è 3
í 3
î 3
ⁿ 3
n 3
ò 3
p 3
û 3
i̍ 2
ì 2
ĩ 2
j 2
ⁿ 2
n 2
n̂ 2
ã 1
l 1
n 1
ń 1
u̍ 1
ṳ̀ 1
ṳ̄ 1
[ 本帖最後由 Bodhisatua 於 2009-11-27 23:55 編輯 ] |
 发表于 2009-11-27 23:38
发表于 2009-11-27 23:38
 发表于 2009-11-28 06:29
发表于 2009-11-28 06:29



{kind=link}
{kind=link}
{kind=link}